Replicación del ácido desoxirribonucleico (DNA)
La preservación de las especies sobre el planeta implica la necesidad de la reproducción de las diferentes formas de vida. Cada especie tiene características únicas, que en su mayoría son el resultado de la expresión de su carga genética. Desde este punto de vista, uno de los procesos biológicos celulares más relevante es la replicación del
DNA, molécula que guarda en su secuencia de bases la información genética que distingue a los individuos como integrantes de una especie en particular. El DNA está formado por dos hilos de nucleótidos enrollados uno sobre el otro, formando una hélice doble guardada en la profundidad de las células. En cada ciclo celular, las hebras de la molécula de DNA se separan y se copian con la más alta fidelidad, para luego volver a reformar la doble hélice,
en una danza eterna que mantiene vigente la vida hasta nuestros días.
CICLO CELULAR EN ASOCIACIÓN CON LA REPLICACIÓN
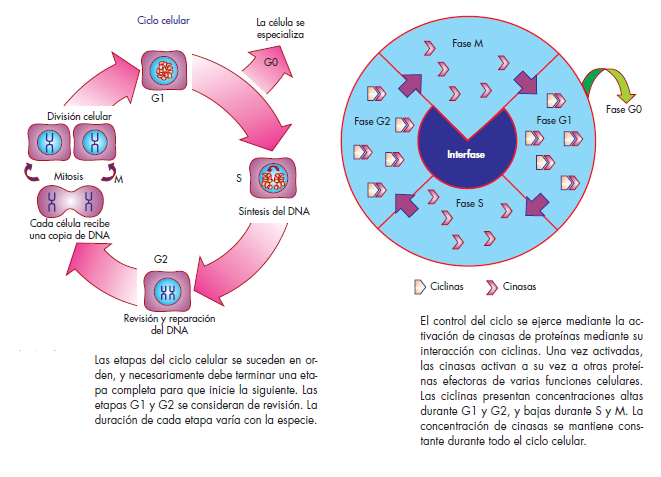
Todos los organismos vivos tienen un ciclo de vida, compuesto de etapas que se van alcanzando de manera consecutiva en el tiempo. Las células, como componentes
básicos de todos los organismos, también atraviesan fases temporales que conforman su ciclo denominado ciclo celular.
En la fase G1, la célula inicia su ciclo de vida con un tamaño reducido. Durante esta etapa, se dedicará a aumentar su tamaño y a llevar a cabo las funciones celulares típicas de la interfase. En algún momento de G1, las células pueden entrar en una etapa de especialización denominada G0, donde realizarán funciones específicas y no se dividirán por un tiempo indeterminado. En este caso están las neuronas y las células hepáticas maduras.
Las células que no entran en G0 continúan a la fase S,
que es la etapa en la cual se replica el material genético.Durante este periodo, la célula debe asegurar que todo el DNA que conforma su genoma se copie, generando dos
moléculas idénticas. En la siguiente fase, denominada G2, se activan los
mecanismos de revisión y reparación del genoma, para asegurar en la medida de lo posible que las moléculas de DNA generadas en la fase S no contengan errores de copia que sean incompatibles con la supervivencia de la descendencia. En esta fase es cuando se activan también los mecanismos de división celular que darán origen a las
células hijas.
Finalmente, en la fase M se lleva a cabo la división física de la célula original, que ahora da lugar a dos células hijas, cada una de las cuales contiene una de las copias de DNA que se generaron durante la fase S.
ORIGEN DE LA REPLICACIÓN
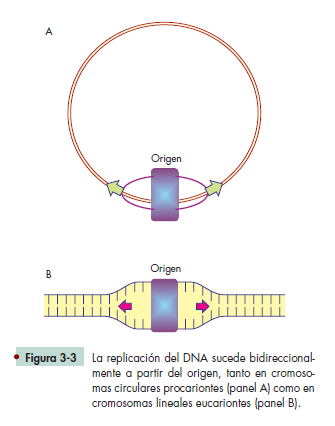
El DNA es una hebra doble de nucleótidos con una secuencia determinada, que no tiene señales adicionales que diferencien las funciones de una secuencia en particular.
Se sabe que en esas hileras de nucleótidos están ubicados los genes, y que cada uno de ellos proporciona información para construir organismos, pero no hay señales que muestren dónde inicia y dónde termina determinado gen; del mismo modo, sabemos que, además de genes, el DNA también contiene secuencias específi cas que no generan productos génicos, pero que son primordiales para que los genes puedan regularse de manera adecuada. Entre otras secuencias de esta naturaleza, está el llamado origen de replicación, que es el sitio donde debe iniciar la copia del material genético, en cada ciclo celular.
ENZIMAS PARTICIPANTES EN LA REPLICACIÓN
La replicación del DNA es un proceso dinámico, que
comprende la participación de varias enzimas que se
coordinan para generar una copia casi siempre 100%
idéntica a la molécula original. Al fi nal del proceso, cada
una de las copias nuevas forma una doble hélice con la hebra original que le sirvió de molde. El conjunto básico de las enzimas que participan en el proceso se conoce como maquinaria de replicación, y está formada por las
siguientes proteínas
Polimerasa de DNA
se conocen tres tipos de polimerasas de DNA, caracterizadas en E. coli , denominadas I, II y III, según el orden en que fueron descubiertas. Las de tipo I y II funcionan sobre todo en los procesos de reparación del DNA, en tanto que la de tipo III es la encargada de catalizar la elongación de la cadena del DNA durante el proceso de replicación. Esta proteína es de estructura compleja; está formada de varias subunidades, que juntas constituyen una molécula de 600 kDa aproximadamente. Las subunidadesα,εyθforman el núcleo de la enzima, que contiene las actividades de polimerización 5′→3′yde exonucleasa 3′→5′, que le permiten agregar nucleó-tidos trifosfatados a la cadena en crecimiento, y retirar en el momento cualquier nucleótido que se haya inser- tado de manera equivocada (corrección de lectura). La subunidad β es un homodímero con estructura en forma de aro, que tiene la capacidad de abrirse y cerrarse alrededor del DNA, y luego deslizarse por toda la longitud de la molécula, con el centro enzimático de la enzima unido a ella (fi g. 3-4). A esta capacidad de mantenerse sobre la cadena molde se le llama procesividad. Las
γ , δ ,δ′ , χ y ψ forman en conjunto el complejo γ , cuya función es abrir y ubicar a la subunidad β sobre el dúplex de DNA, en una reacción que requiere ATP, y descargarla cuando se ha completado el proceso de replicación.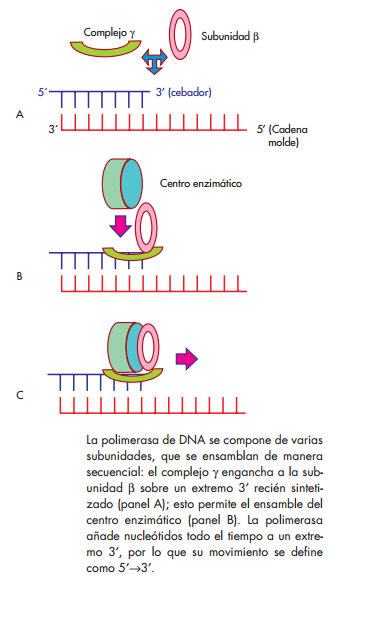
γ , δ ,δ′ , χ y ψ forman en conjunto el complejo γ , cuya función es abrir y ubicar a la subunidad β sobre el dúplex de DNA, en una reacción que requiere ATP, y descargarla cuando se ha completado el proceso de replicación.
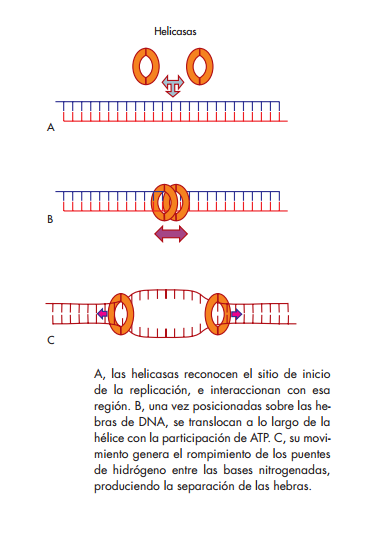
Helicasas
Son proteínas que utilizan la energía de los enlaces del ATP para catalizar el desenrollamiento parcial y transi torio de moléculas de ácidos nucleicos de doble hebra.
Para realizar su función, las helicasas por lo general se reúnen en estructuras hexaméricas que adquieren una forma tridimensional de anillo. El hexámero contiene un dominio de unión al origen, que reconoce el sitio de origen de replicación y le permite ensamblarse a él. Este ensamble produce la distorsión y separación de la doble hebra de DNA, en presencia de ATP y iones Mg ++ Una vez sobre el DNA, las helicasas pueden desplazarse a lo largo de cada una de las hebras en dirección 5′→3′. A medida que se desplazan, utilizan energía química que proviene de la hidrólisis del ATP para romper los puentes de hidró-
geno entre las bases, produciendo así la abertura de la molécula.
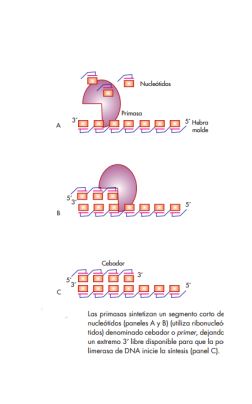
Primasas
Las primasas son enzimas que catalizan la formación de pequeños segmentos de RNA, de unos 11 nucleótidos de longitud, llamados cebadores o primers, y que son absolutamente indispensables para que la polimerasa de DNA funcione, ya que ésta, como se mencionó, requiere la presencia de un extremo 3′ libre preexistente para iniciar la síntesis de DNA.
Proteínas ssb
Llamadas de este modo por las siglas en inglés de “proteína estabilizadora de la hebra simple” (single strain binding protein), son moléculas que se unen cooperativamente a la hebra abierta del DNA, impidiendo que tome su confi guración de hebra doble. Se presentan en forma de homotetrámeros, cada uno de los cuales abarca alrededor de 35 nucleótidos, a los que se unen sin ningún tipo de especifi cidad.
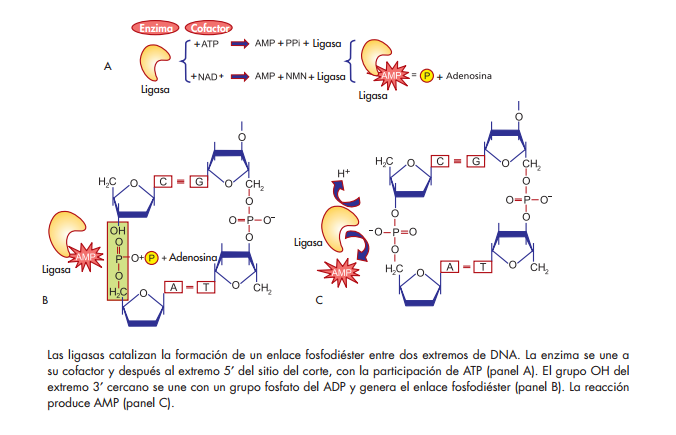
Ligasas
Son enzimas que catalizan la formación de enlaces fosfodiéster entre los extremos de dos hebras de ácidos nucleicos. Hay dos clases, según la fuente de energía que prefi eren: las que utilizan NAD+ como cofactor y que existen en las bacterias, y las que usan ATP como cofactor, específi cas de los eucariontes. Su mecanismo de acción requiere tres pasos:
a) Formación de un enlace covalente entre la enzima y su cofactor. Esto produce la liberación de una molécula de PPi.
b) Transferencia del nucleótido del AMP al fosfato del extremo 5′ del DNA que se va a sellar.
c) Formación de un enlace fosfodiéster con la liberación de AMP
Topoisomerasas
Son enzimas que cortan y ligan el DNA cambiando su topología, sea induciendo la formación de giros o relajando superenrollamientos. El corte se hace a nivel del enlace fosfodiéster, transfi riéndolo a un residuo de tirosina de la enzima, en un proceso que requiere la presencia de iones magnesio. Según el efecto que tienen las topoisomerasas sobre la molécula de DNA, se han clasifi cado como sigue: • Tipo I: interaccionan de preferencia con DNA superenrollado, induciendo un corte en una de las hebras, pasando la otra hebra por el corte, y volviendo a sellar, relajando de este modo la molécula. No requieren ATP para funcionar. • Tipo II: al contrario del tipo I, éstas se unen a DNA relajado, induciendo superenrollamientos. Sin embargo, en presencia de DNA superenrollado negativamente, inducen corte y ligamiento de la doble hebra, produciendo su relajación, en un proceso que requiere la presencia de ATP. En las bacterias, las enzimas girasas son topoisomerasas de este tipo.









 en
en

